Watch out for Reference Types
I work in the Seller Growth team in Flipkart. We help them improve their business by showing them different metrics and recommendations based on their and their peers’ performance on our platform. Some days back, our product-manager came up with a concept, a central page, where we would be surfacing an aggregate view of all the recommendations personalized for the sellers. We already had our backend which generates various recommendations based on different cohorts. They had to make a new system to give sellers new goals and benchmark them on the basis of their performance. This page had a beautiful UX. We implemented shimmers, animations, and confettis to be shown when the seller achieves his goal and has a benchmark upgrade. This page had to be mobile responsive to be supported both on desktop and mobile browsers. Also, Flipkart’s seller app should be able to open this page inside the mobile application instead of building a page of their own. We are constantly trying to build our web pages that will be compatible across all devices and platforms. This was one of the first pages (the first in the Growth team) which was built like that. We wanted the release to be successful, with low user NPS (Net Promoter Score) both from product and user experience point of view.
Because we were showing recommendations to our sellers before, a major part of our backend was already built. We had to aggregate all those recommendations and show it in the UI. This would be a heavy computation if performed on the client side (in the user's browser) and will hamper the user experience. We have a middleware (built with node.js) for this purpose. In a simplified way, you can consider this middleware, a server, without a database, which fetches data from other microservices and sends them to the client (browser) post aggregation and customization.
We (me and a fresher I was mentoring) built this page. We tested it on local, stage environments and the production environment. Then after successful UAT with all the stakeholders we released it for a few hundred sellers (we have a control mechanism, where we can release a feature in steps) on a Friday evening. I shut down my laptop, went for a walk, came back and started watching some movies on Netflix. I had my dinner. I was going to go to bed, when I got a call at 11pm from my junior (the guy I was mentoring). “Hi, the recommendations seem to have broken in production. Sellers do not see the data provided by the backend. The experience is intact, but the data surfaced is wrong. I have been debugging this for an hour and I am still not able to find the bug.”
We have built a support dashboard, where we can see the same view the seller is seeing. This is meant for internal use by the seller support agents, the product managers, and the developers. There I could easily see the issue. The first two big sellers I searched for had the exact same recommendation data. How is this possible? We had tested it already. To test it again locally, I hardcoded their userIDs, fired up my server, and opened the page in my browser. But here everything looks good. All the recommendations were surfacing correctly. But on the support dashboard, we could see it was broken.
Two small pieces of information at this point. Every time, I needed to hardcode a production seller in my local development, I had to restart my local server. The support dashboard was pointing to an ELB which had thirty production boxes under it.
So where is the bug? Of course, it was somewhere in the middleware code because the UI was not breaking, only the information provided by the API was wrong. I started debugging. At first glance, everything looked perfect. Finally, after debugging for half an hour I figured it out. We called different backend systems for fetching different recommendations and from all these recommendations, we extracted a few information like the number of listings it would affect, the potential improvement in sales a seller could see, the seller’s progress in implementing the recommendation, and the expiry date, etc. A typical backend response would look like the below figure.

[Figure1] A typical backend response
We had a local configuration map for all the recommendations we generated inside a constant.js file. This map consisted of a few keys like the title, subtext, navigation links.

[Figure2] Config Map
After extracting the information from the APIs we combined the response and map to a suitable structure for UI. That processor looked like the following.
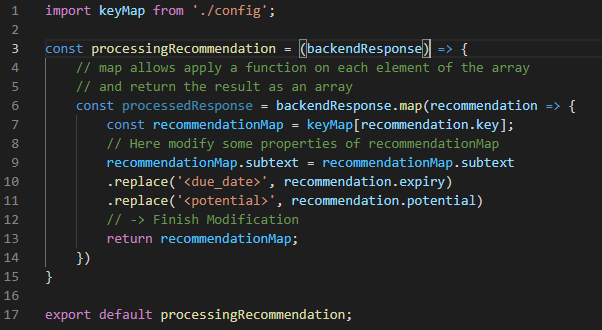
[Figure3] Processing the response
Pause for a while here. Did you figure out what I was doing wrong? Yes, you are right. The bug lies on line number 7. The keyMap is a map of objects and objects are reference types in JavaScript. That means, when you import the data type inside another file or pass it to a function, it will forward a memory pointer instead of sending a cloned value. Any modification we do to the recommendationMap property will reflect inside the corresponding object in the keyMap as well. Inside a production box, for the first lucky seller, the response will be accurate. For the subsequent visitors, for the same set of recommendations, in line number 9-11 the subtext will not have any <due_date> or <potential> substring to be replaced (because the first request would have already replaced them). So, they will see the response exactly similar to the first seller for the same recommendation.
Now the big question is why were we not able to find out this bug during development? It was because, in each of both stage and prod testing environments, we had only one test seller which had data. So we did not log out and log in to check for another user, without turning off the server (turning off the server will reset the map to the same value as constant.js). Also, while hardcoding the live sellers in the local environment, we had to restart the server.
The fix is of course to use any utility library which provides deep cloning like lodash. At this point, people can ask, why you didn’t use the spread operator. The answer to that will be that the spread operator only copies primitive values to one level. What if you have further nested structures?
How can we avoid such errors in the future? Always keep in mind reference-type structures can always create such problems. In situations where you need to modify any property inside it, you should always clone them. Also, writing good unit test cases is worth the effort. Whenever you are testing any function, you can mock the imports. You should always have one unit test case at least, which clones these imports and reference type parameters passed to the functions, before invoking the function you are testing. After invoking the function you should test if the cloned values remain unchanged. This will guarantee the function you are testing is a pure function (A pure function returns identical values for identical arguments with no variation with local static variables, non-local variables, mutable reference arguments, or input streams) or at the very least it will ensure you are not mutating something you do not intend to.
Happy coding.
Comments
Post a Comment